Taking it one step past Part 1: But what’s really in the news?
Besides answering questions like the frequency of how much individual publishers post, what distinct word or word pairs they write most about and the sentiment of their writing, text mining allows us to go one step further.
If we set off from the starting point that each news article is a mixture of topics, and that each topic is in turn a mixture of words, we can measure the relative proportion in coverage one publisher devoted to topic A versus topic B.
Let’s put it more concretely: an article about a court case might be 40% about court procedures and 60% about crime. The mixture of words about court procedures would be more slanted to terms like “judge”, “lawyer”, “appeal”, “defence”, “plea”. The mixture of words corresponding to the topic of crime would, theoretically, be more prone to contain “stab”, “knife”, “attack”. Statistical models that estimate i) the mixture of words that are likely to comprise a topic and ii) the relative proportion of those topics in an article are called topic models.
One very good implementation of a topic model in R is called a latent Dirichlet allocation and is available in the topicmodels package. (If you’re curious, this is a good resource on LDA.)
Step 1: Finding out the topics.
We’ll start with the same dataset as in Part 1. Actually, we’ll use the unnested words, which was one of the first things we did in Part 1. We’ll feed this list of individual words, the article and publisher they come from to the LDA algorithm.
The only other input we specify for the algorithm is how many topics it should search for. This is where some of subjective judgment calls come in. Too few topics, and you risk blending everything together. Too many, and you risk dilluting the meaning in groups of words.
After some experimentation, I settled on telling the LDA algorithm to search for 6 topics. Here are the top 12 words that are most common within each topic:
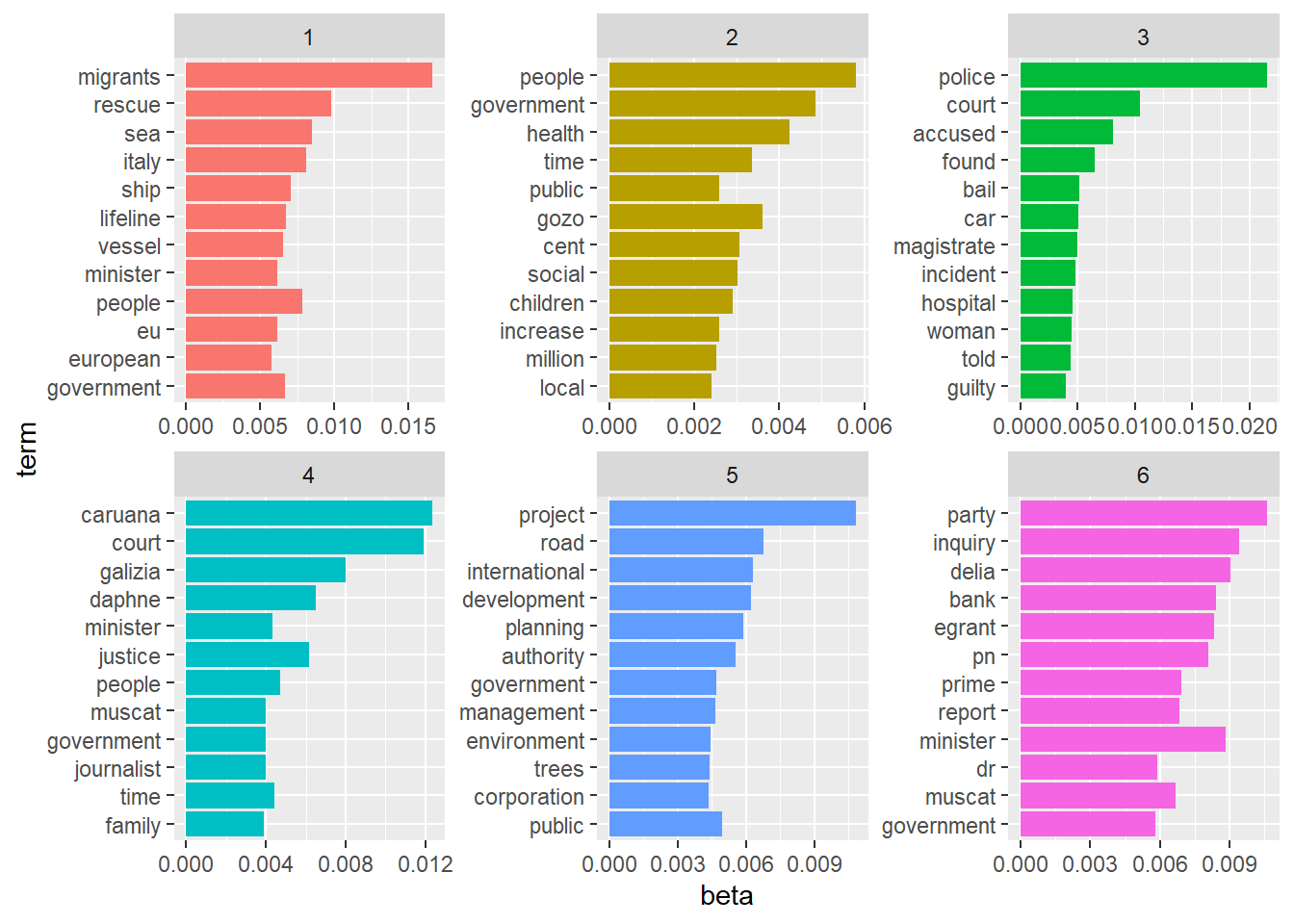
And here’s my subjective conclusion about what each topic is “about”.
- Topic 1: Migration
- Topic 2: General Government Issues/News
- Topic 3: Court/Crime news
- Topic 4: The Daphne Caruana Galizia case
- Topic 5: Infrastructure/Environmental news
- Topic 6: Politics/Corruption/Internal PN strife/Egrant related coverage
Taking the entire material published by each organisation, we can visualise the proportion each topic has featured in their reporting:
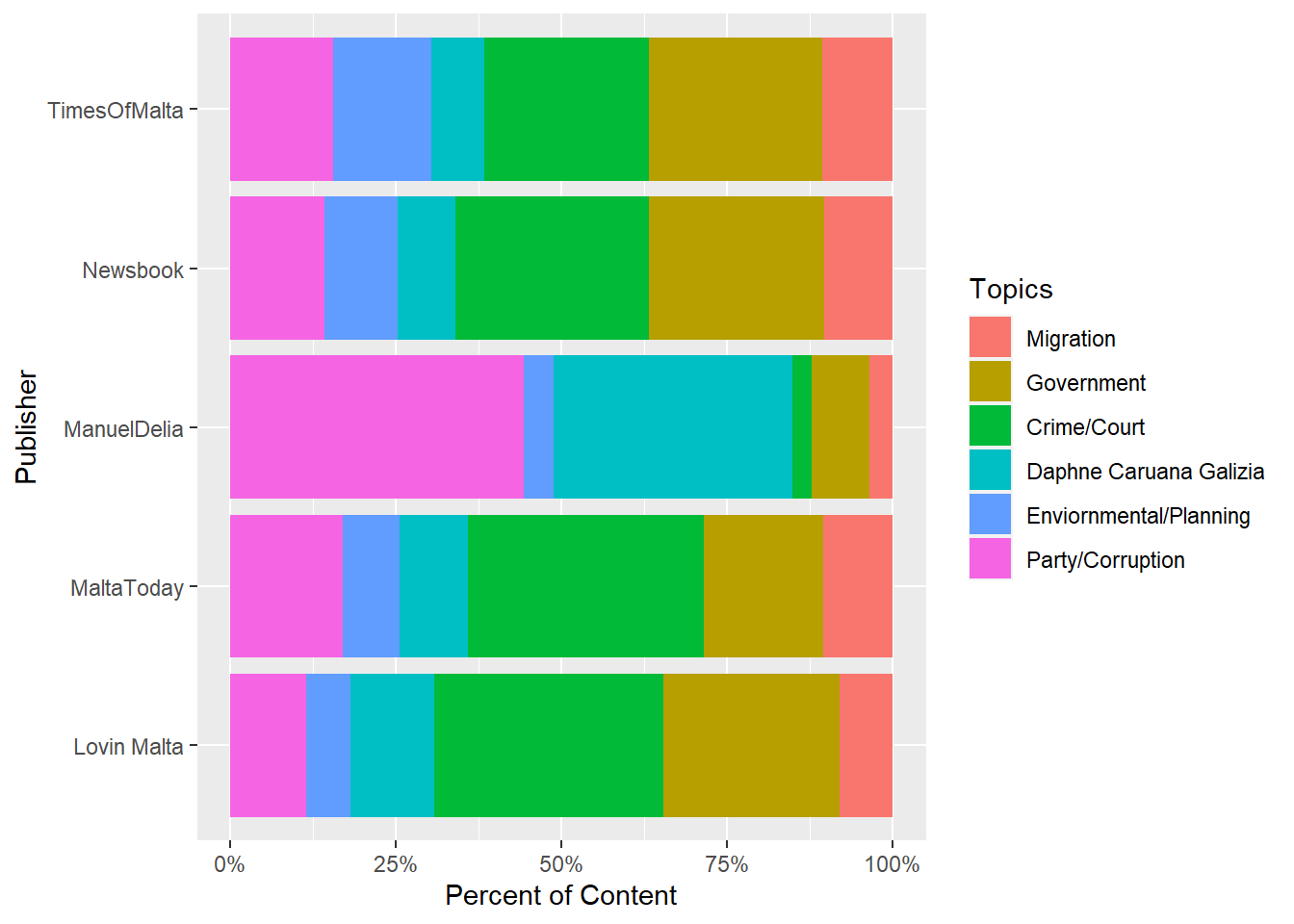
In large part, most topics got around a relatively equal share of ‘newstime’ this summer, with the notable exception being the prolific coverage of the Daphne Caruana Galizia Case (36%) and Party/Corruption (44%) on ManuelDelia.com
Other notable things include:
- Malta Today focusing less on government news, and more on court news.
- Lovin Malta having the lowest share of Party/Corruption oriented topics and the second lowest share of migration related topics.
- Newsbook and Times of Malta’s similar results, which is probably due to the sheer amount of continuous output from those two newsrooms.
What Topic Modelling isn’t about
Knowing that a website has x proportion of content about a topic doesn’t really tell you much about the quality of that content, or the bias in it. Take political party news websites as an example. Both might have roughly the same amount of content on government issues, but on one website, that content will be almost exclusively in support of the government, while on the other it will be almost exclusively in condemnation of it.